
The Agentic Race Condition
We built asynchronous workers. Now we have to stop them from corrupting each other. Here is the hardcore engineering guide to handling database concurrency and Mutex locks in multi-agent systems.

On Tuesday, we solved the Human-in-the-Loop problem by building the Human API. We effectively turned our agents into asynchronous, long-running background processes that can serialize their state, go to sleep, and wait for human governance.
Now that your agents are running in the background, your product team is going to do what product teams always do: they are going to scale it.
Instead of one agent, you now have a swarm of 50 asynchronous agents constantly churning through support tickets, billing queues, and CRM updates.
And immediately, your database state is going to corrupt.
Why? Because you just introduced classic distributed systems concurrency issues to an architecture that inherently relies on high-latency operations. You have introduced The Agentic Race Condition.
Today, we are diving into the hardcore backend reality of multi-agent scaling. We are going to explore why LLM latency makes race conditions catastrophically worse, and exactly how to implement Distributed Locks (Mutex) to protect your enterprise state.
Chapter 1: The AI Concurrency Nightmare
To understand the threat, we need to look at a classic “Read-Modify-Write” race condition, but viewed through the lens of Agentic AI.
Imagine two separate agents operating in your swarm:
Agent A (The Billing Agent): Triggered by a failed Stripe webhook. Its job is to read a customer’s account state, apply a $50 late fee, and update the database.
Agent B (The Support Agent): Triggered by a customer email. Its job is to read the same customer’s account state, apply a $20 goodwill credit, and update the database.
Both agents wake up at the exact same millisecond.
Agent A reads the database. The customer’s balance is
$100.Agent B reads the database. The customer’s balance is
$100.Agent A passes the
$100state into its LLM context window to determine the new balance.Agent B passes the
$100state into its LLM context window to determine the new balance.Agent B finishes its inference first. It writes the new balance:
$100 - $20 credit = $80.Agent A finishes its inference two seconds later. It writes its new balance:
$100 + $50 fee = $150.
The Result: Agent A just completely overwrote Agent B’s transaction. The customer was charged the $50 fee, but the $20 credit was annihilated from existence. Your database state is now factually incorrect.
Chapter 2: The LLM Latency Window
Race conditions are not new. Standard microservices deal with this every day.
But here is why this is a nightmare for AI: The latency window.
In a standard deterministic Python microservice, the time between the SELECT (read) and the UPDATE (write) is measured in microseconds. The window for a collision is incredibly small.
With an AI Agent, the time between reading the state and writing the state involves a round-trip inference call to an LLM. Depending on the model, context size, and token generation speed, this operation can take 3 to 15 seconds.
Your critical section is practically an eternity. In a high-throughput enterprise swarm, the probability of two agents colliding within a 10-second latency window approaches 100%.
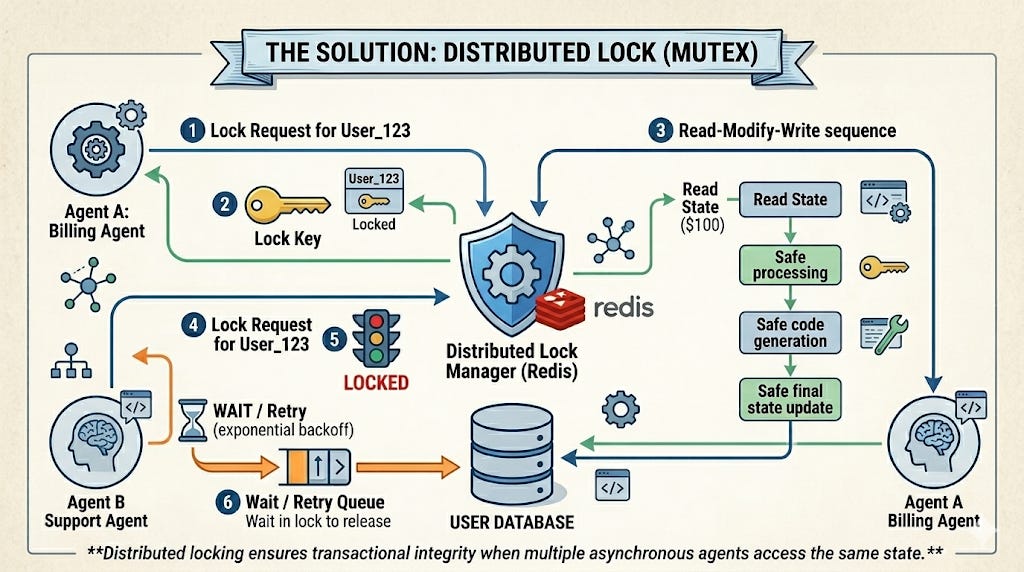
Chapter 3: Implementing the Agentic Lock (Mutex)
You cannot let agents blindly mutate state. You must implement a Distributed Lock (Mutual Exclusion, or Mutex).
Before an agent is allowed to invoke its LLM chain to process a specific entity (like a user_id or invoice_id), it must acquire a cryptographic lock on that entity. If another agent tries to process that same entity, it must be forced to wait.
Here is how you engineer this using Redis as your distributed locking mechanism:
Python
import redis
import time
from contextlib import contextmanager
# Connect to the Redis cluster
redis_client = redis.Redis(host='localhost', port=6379, db=0)
@contextmanager
def acquire_agent_lock(entity_id: str, lock_timeout: int = 30):
"""
Attempts to acquire a Redis lock for a specific entity before allowing
an AI agent to process it.
"""
lock_key = f"agent_lock:user_{entity_id}"
lock_acquired = False
try:
# Standard distributed lock pattern (SET NX EX)
# NX = Only set if it doesn't exist
# EX = Auto-expire after X seconds (Crucial for AI deadlocks!)
lock_acquired = redis_client.set(lock_key, "LOCKED", nx=True, ex=lock_timeout)
if not lock_acquired:
raise ResourceWarning(f"Entity {entity_id} is currently locked by another Agent. Aborting run.")
yield True
finally:
# Always release the lock when the agent finishes, even if it crashes
if lock_acquired:
redis_client.delete(lock_key)
Now, we wrap our agent’s execution graph inside this lock:
Python
def run_billing_agent(user_id: str):
try:
with acquire_agent_lock(user_id, lock_timeout=45):
# The agent safely owns this user's state for the next 45 seconds.
current_state = db.get_user(user_id)
# --> 10 SECOND LLM INFERENCE CALL <--
new_state = agent_graph.invoke(current_state)
db.update_user(user_id, new_state)
except ResourceWarning as e:
# Agent B hit the lock!
# Push this task to a Dead Letter Queue to retry in 60 seconds.
queue_for_retry(user_id, "billing_task")
If the Support Agent tries to access this user while the Billing Agent is currently “thinking”, the Redis lock rejects the attempt. The Support Agent is safely routed to a retry queue.
Chapter 4: The Deadlock Trap (Why TTL is Mandatory)
Notice the ex=lock_timeout parameter in the Redis configuration above. This is arguably the most critical line of code in the entire architecture.
LLMs are inherently unstable. They hallucinate. API providers rate-limit them. Sometimes, the LangGraph chain just gets stuck in an infinite tool-calling loop.
If your agent acquires a lock on a customer’s account, and then the OpenAI API hangs, your agent will never reach the finally block to release the lock. That customer’s account is now permanently frozen. No other agent or human can modify their data. You have created a Deadlock.
To prevent this, every Agentic Lock must have a strict Time-To-Live (TTL).
If you estimate your agent’s maximum workflow should take 20 seconds, you set the lock TTL to 45 seconds. If the agent hangs, Redis will automatically evict the lock at the 45-second mark, self-healing the distributed swarm and allowing other agents back in.
The Executive Mandate: Swarms Require Traffic Control
Building a single agent on your laptop is easy. Building a multi-agent swarm in production is an exercise in hardcore distributed systems engineering.
If you scale your AI workflows without implementing distributed locks, you are actively choosing to corrupt your enterprise data. LLM context windows are not transactional boundaries.
Stop treating your agents like isolated calculators. Treat them like what they are: highly-concurrent, high-latency microservices that need strict traffic control. Lock the state, enforce the TTL, and protect the database.
Conceptually, relying on a Redis mutex to manage state in a multi-agent system is a textbook architectural anti-pattern. It treats a critical invariant - such as a user's balance - as a shared mutable state.
Furthermore, in this design, locks are essentially voluntary. Even if you issue 'cryptographic mutex keys' for write access, it provides zero guarantees against abuse. If multiple autonomous agents retain direct write access to the database, what stops a hallucinating or highly autonomous agent from bypassing the rules or simply evaluating its own transaction as 'critically urgent'?
If we are building a true agentic workflow rather than just a swarm of highly-concurrent, slow microservices, the correct architectural pattern is the single-owner model. We need to introduce a dedicated Account Agent that acts as the sole owner and guardian of the balance's consistency. Instead of direct mutations, other authorized agents should only send requests to this Account Agent. This dedicated agent then serializes, prioritizes, and synchronizes access to the funds, making intelligent decisions based on the user's overall budget and strategic plans.
Anticipating the inevitable performance and reliability arguments:
First, system latency is always bounded by its slowest element. Introducing a specialized, highly cohesive coordinator agent does not create a bottleneck.
Second, the risk of the Account Agent crashing or hanging is trivially solved by maintaining an append-only transaction log. The agent continuously logs its state and automatically recovers upon restart after any crash or LLM hang.
This approach replaces a fragile, superficial patch - like relying on arbitrary Redis TTLs to fix hanging LLMs - with guaranteed, resilient architectural consistency.