
Decoupling LLM Inference Using Message Brokers
We are building futuristic intelligence using 1999 communication patterns.

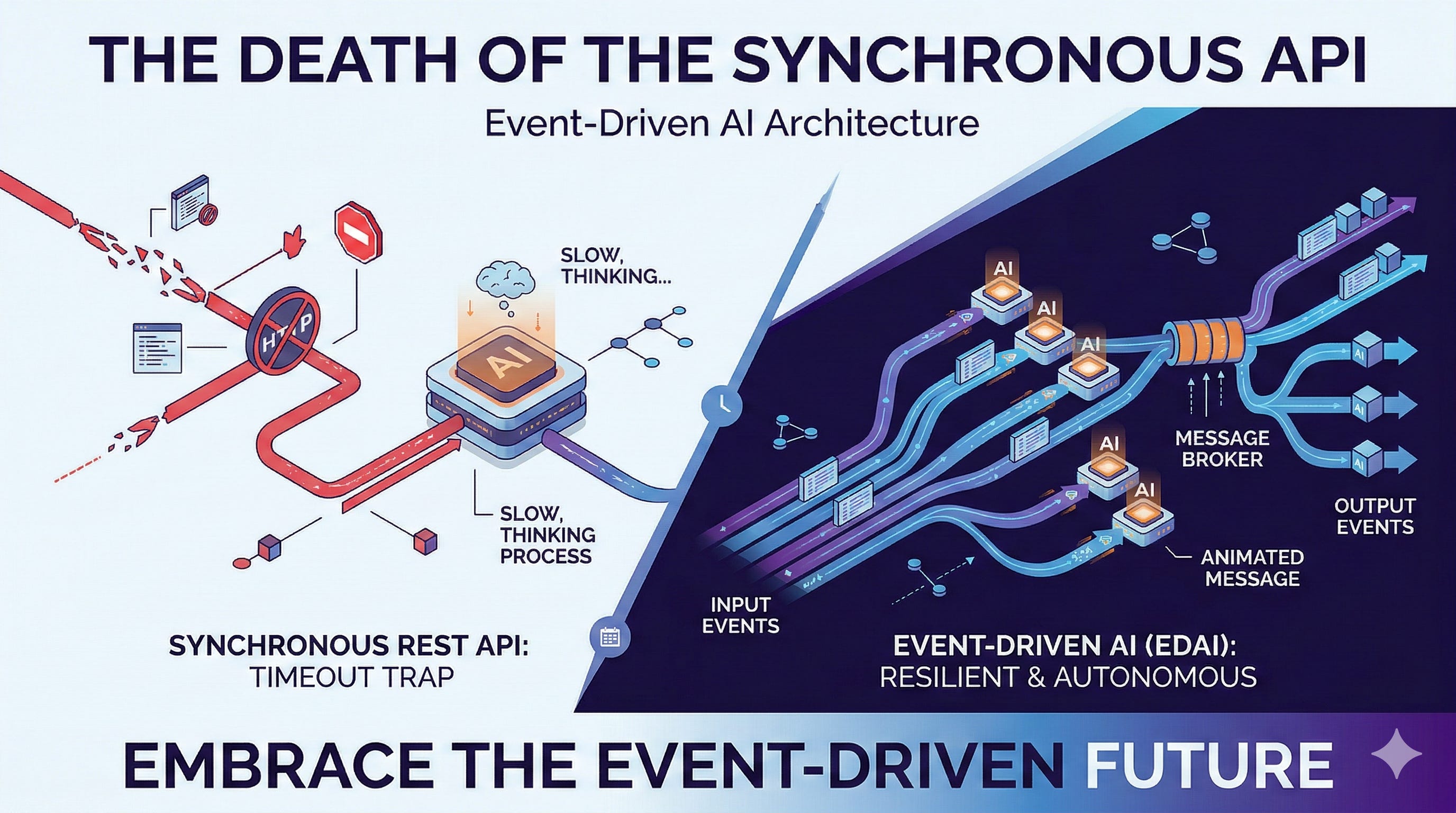
Look at almost any enterprise AI architecture today, and you will see the exact same fundamental flaw. A user clicks a button. The frontend sends a synchronous REST API request to a backend. The backend sends a synchronous HTTP request to a Large Language Model (LLM).
And then, the entire system holds its breath.
For five seconds, ten seconds, sometimes thirty seconds, the main thread is blocked. The database connection is held open. The user stares at a spinning loading wheel, wondering if the application has crashed, while the server waits for the model to finish “thinking.”
This is the Request-Reply Fallacy.
We took the most powerful cognitive engines ever created and forced them to communicate like legacy web servers. We are treating multi-step reasoning processes as if they were simple database SELECT statements.
If you want to build truly autonomous systems, you have to accept a hard architectural truth: Cognition cannot be synchronous.
The future of AI architecture is not the REST API. It is the Event Stream.
The Origins of the Anti-Pattern
Why did the entire industry default to this brittle architecture? Because it is what we know.
For twenty years, the Request-Response lifecycle of HTTP has been the undisputed king of web development. A client asks for a resource; the server fetches the resource and returns it immediately. This works perfectly when the backend task is deterministic and fast—like fetching a user profile or submitting a form.
But AI reasoning is neither deterministic nor fast.
When you ask an Agentic Swarm to “Analyze these three financial reports, query the live database for anomalies, and summarize the findings,” you are not requesting a resource. You are initiating a complex, multi-step cognitive workflow. The LLM might need to make three sequential tool calls, wait for an internal API to respond, evaluate its own output, and self-correct.
Forcing this unpredictable, variable-latency process into a synchronous HTTP request is an architectural disaster waiting to happen.
The Problem with Holding Your Breath
Synchronous AI architecture collapses in production for three distinct reasons.
1. The Timeout Trap
HTTP was designed for quick data retrieval, not deep reasoning. Most enterprise API gateways, load balancers, and frontend clients have aggressive, hardcoded timeouts—often set between 15 and 30 seconds.
If you ask an LLM to perform a task that requires multiple tool executions (e.g., writing Python code, executing it in a sandbox, and interpreting the results), it will frequently hit that timeout boundary. The connection is brutally severed.
Your backend code didn’t fail. The LLM didn’t fail. The infrastructure failed the AI because the protocol ran out of patience. You are left with a frustrated user and a system that burned expensive tokens for a result that was never delivered.
2. The Thundering Herd & Token Exhaustion
When a massive traffic spike hits a synchronous AI system, every single request opens a new, long-running connection.
If 1,000 users ask your AI a question simultaneously, your application attempts to execute 1,000 LLM calls at once. Two things happen immediately:
Thread Starvation: Your application servers quickly run out of worker threads trying to hold 1,000 open connections to an external API.
Rate Limiting: You instantly breach your LLM provider’s Tokens-Per-Minute (TPM) or Requests-Per-Minute (RPM) limits. The provider responds with
HTTP 429 Too Many Requests.
The system grinds to a halt, taking your entire product down with it. Synchronous architectures weaponize your provider’s rate limits against you.
3. The Illusion of Autonomy
Perhaps the most damning flaw of the REST API is that it makes true autonomy impossible.
A system that only acts when explicitly queried via a REST endpoint is not an “agent.” It is just a very smart script. It is entirely reactive. True autonomy requires observation. An agent must be able to react to the world without a human being explicitly pressing “Enter.”
To fix this, we must completely decouple the Request from the Reasoning.
Architecting the Event-Driven AI (EDAI)
In an Event-Driven AI Architecture, the LLM is no longer a blocking function call. It is an asynchronous consumer sitting on a distributed message bus.
Here is how the architecture must shift to support production-grade autonomy.
Step 1: The Ingress (Acknowledge, Don’t Block)
When a user submits a complex task, your backend must immediately refuse to call the LLM.
Instead, the backend validates the payload, generates a unique TaskID, and publishes an event (e.g., FinancialAnalysisRequested) to an event broker like Apache Kafka, RabbitMQ, or AWS EventBridge.
The backend immediately returns an HTTP 202 Accepted to the frontend, along with the TaskID.
The user sees: “The Agent has begun investigating your request.” Zero latency. Zero blocked threads. The web server has done its job in 50 milliseconds and is free to handle the next user.
Step 2: The Cognitive Workers (The Swarm)
Deep in your infrastructure, decoupled from your public-facing web servers, sit your autonomous AI agents. These agents are subscribed to specific event topics.
When the FinancialAnalysisRequested event hits the queue, an available “Financial Planner Agent” picks it up. Because it is decoupled from the user’s HTTP request, the agent can take exactly as much time as it needs.
It can spend two full minutes querying databases. It can spawn parallel sub-tasks to other queues. It can retry failed API calls. It operates entirely outside the constraints of web timeouts and impatient API gateways.
Step 3: The State Manager & UX (WebSockets and SSE)
“But wait,” you might ask, “how does the user get the answer if the HTTP request was already closed?”
This is where modern frontend architecture meets Agentic AI. While the cognitive worker is processing the event in the background, the frontend uses the TaskID to open a WebSocket connection or a Server-Sent Events (SSE) stream to a State Manager service.
As the AI agent works, it emits intermediate events back to the message broker:
Event: ToolCalled (Querying Q3 Revenue)Event: ReasoningStep (Comparing Q3 to Q2)Event: TaskCompleted (Final Summary)
The State Manager pushes these updates to the frontend in real-time. The user doesn’t stare at a blank screen; they watch a live progress indicator of the agent’s “thought process.” When the final TaskCompleted event arrives, the UI updates with the answer.
Managing Failure: Cognitive Retries and Dead Letter Queues
In a synchronous system, if an LLM hallucinates or an API fails, the user gets a generic “500 Internal Server Error.”
Event-Driven AI gives us the architectural tools to handle cognitive failures gracefully.
When an agent pulls an event from the queue, it attempts to execute the reasoning loop. But what if the internal database is down, or the agent gets trapped in a hallucination loop?
Because we are using a message broker, the event is not lost. If the agent fails to successfully acknowledge the task, the message broker can apply Exponential Backoff. It will wait 10 seconds, then hand the event to a different agent worker to try again.
If the task fails three times, the event is routed to a Dead Letter Queue (DLQ).
A DLQ is a specific holding area for failed cognitive tasks. An engineering team (or even a highly advanced “Critic Agent”) can monitor the DLQ, inspect the exact context that caused the agents to fail, fix the underlying prompt or MCP tool, and then replay the events.
You never lose user intent. You simply pause it, fix the logic, and let the system resume.
The AI Nervous System: Proactive vs. Reactive
Moving to an EDAI architecture fundamentally changes what your AI is capable of. When your agents are plugged directly into an event bus, they stop being reactive chatbots and start becoming proactive observers of your enterprise infrastructure.
Imagine an e-commerce platform. In a legacy synchronous system, a supply chain manager has to open a dashboard, type a prompt into an AI assistant, and ask, “Are we low on stock for SKU 123?”
In an Event-Driven AI system, the AI does not wait to be asked.
When a customer buys the last item, the inventory database emits a StockLevelZero event to the central Kafka cluster. A “Supply Chain Agent” is subscribed to this topic. It catches the event in real-time, queries the historical sales data to predict future demand, generates a draft purchase order, and emits a ReorderProposed event to a Slack channel for a human to approve.
The system is no longer waiting for prompts. It is reacting to the pulse of the enterprise.
Concurrency and Cost Control
EDAI is not just about reliability; it is about financial survival.
If you have a massive traffic spike, an event-driven system protects your LLM infrastructure. Those 10,000 sudden user requests simply queue up in the message broker.
Your cognitive workers pull from the queue at a strictly controlled, predictable pace that perfectly matches your OpenAI or Anthropic API rate limits.
The users might wait 15 seconds instead of 5 seconds for their result, but the system remains perfectly stable. You never crash. You never exceed your token limits. You trade brittle, immediate responses for delayed, guaranteed reliability.
You control the throughput; the traffic spike does not control you.
The Core Principle: Decouple Intelligence from the Interface
The transition to Event-Driven AI requires us to unlearn the most ingrained habits of traditional web development.
Stop treating Large Language Models like standard database queries. Deep reasoning takes time. Complex tool execution takes time. Context retrieval takes time.
If you tie the intelligence of your system to the lifespan of an HTTP request, you will build brittle, expensive, and deeply frustrating products. You will spend all your time fighting timeouts, managing thread pools, and apologizing for dropped requests.
Drop the synchronous APIs. Embrace the message queue. Decouple your intelligence from your interfaces.
Let your web servers respond instantly, and let your agents take the time they need to think.