Why AI Agents Need an "Undo" Button
You can't fix a multi-step LLM crash with a simple try/except block. Here is how to build Agentic Rollbacks.

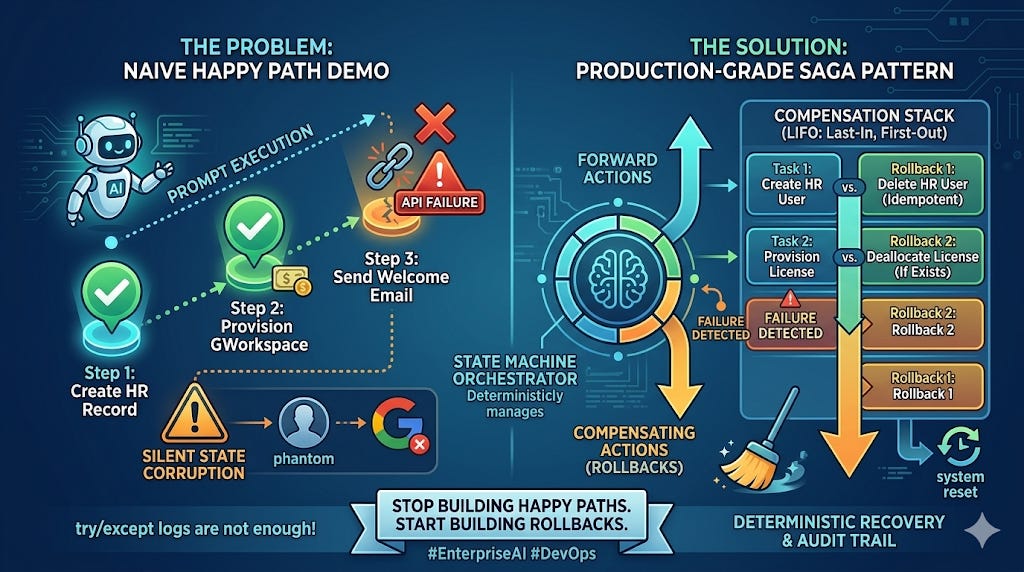
We have all written this exact script.
You are building an AI agent to automate a complex, multi-step enterprise process. For example, employee onboarding. In a local Jupyter notebook, your thought process is linear and optimized for the “Happy Path” where everything works flawlessly.
You give your Large Language Model (LLM) access to three internal tools and write a simple, powerful prompt:
Plaintext
Goal: Onboard new hire Ashu Kumar (ashu@company.com).
1. Create a user account in the internal HR database.
2. Provision a Google Workspace email and license.
3. Send a welcome message to the new hire's personal email.
When you run this script locally, it works. The agent happily marches through steps 1, 2, and 3. You see green checkmarks and success logs. Your terminal whirs. You feel like a 10x developer, convinced that AGI has solved all your orchestration problems.
Then you push it to production.
On day three, a real workflow hits the server. The agent successfully creates the internal HR database record (Step 1). It successfully calls the Google API and provisions the new email (Step 2). A paid Google Workspace license is allocated. Money has been spent.
But when the agent gets to Step 3 (sending the email), the email API gateway happens to be rate-limited, or the LLM hallucinates a slightly malformed JSON payload that causes the connection to snap.
The agent crashes. You now have a massive, silent, and insidious problem.
In production, your enterprise data is now corrupted. You have a phantom user record in your HR system, a paid Google Workspace license sitting empty, and a new hire who has no idea they were hired.

The Problem: Silent State Corruption
A standard approach in traditional software is to wrap your function in a simple try/except block and log the error to Sentry or a console. But an error log does not refund the Google Workspace license or delete the partially created database row.
Most developers building “AI wrappers” treat the external world as a simple read-only database. They assume the agent’s job is just to summarize text or query information.
True Agentic Platforms, however, are write-heavy. They manipulate the external enterprise. They spend your company’s money, alter your databases, and talk to your customers. And in the world of non-deterministic Large Language Models, assuming success at every step is not just naive; it is a fundamental architectural vulnerability.
When your agent manipulates internal state (e.g., creating a DB entry) and external state (e.g., provisioning a paid external license), it is participating in a distributed system. And distributed systems are brittle. They time out. APIs fail. Edge cases appear.
We cannot let a probabilistic model leave our deterministic enterprise infrastructure in a fundamentally corrupted state just because it got confused on Step 4 of a 10-step prompt. We must move beyond “it worked on my machine” demos and adopt a core distributed systems engineering paradigm: Transactions and Rollbacks.
Since LLMs themselves are stateless and cannot automatically handle atomic transactions, your orchestration layer (your Python state machine) must deterministicly guarantee recovery. You must stop thinking of your agents as moving on a one-way street. Every time your agent takes an action that changes a state (writes to a database, spends money, sends a message), your system must register the exact inverse function required to undo it.
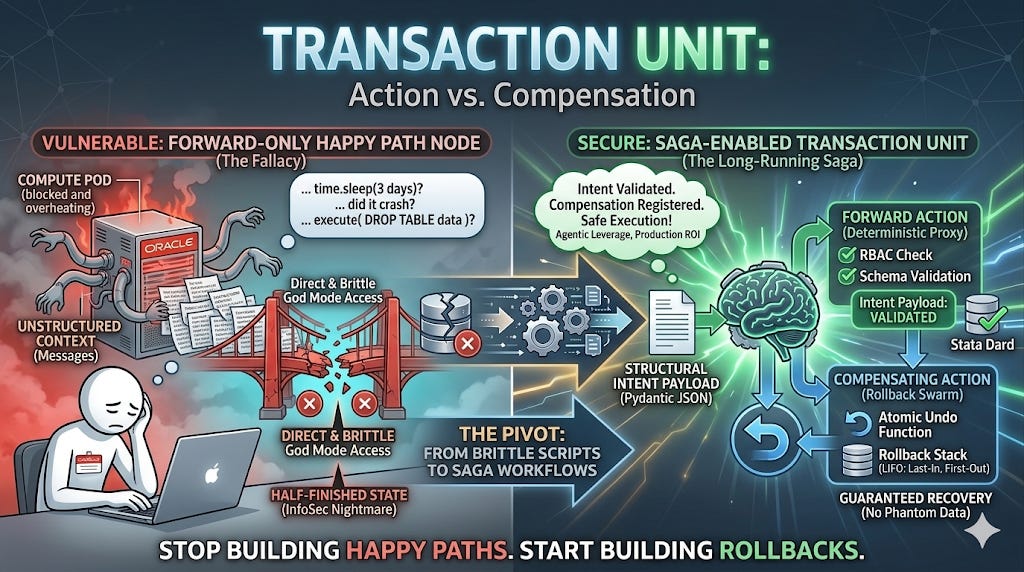
Understanding the Solution: The Saga Pattern
To build truly resilient AI orchestration, we introduce a classic backend software engineering concept: The Saga Pattern.
A Saga is a sequence of local transactions where each step has a corresponding Compensating Action—a specific function designed to perfectly undo whatever the forward step just did.
Think of a Saga as defining a “transaction unit” as a pair of opposing actions. Instead of a single step Provision GWorkspace, you must architect it as (Provision GWorkspace, Delete GWorkspace).
A key constraint of a Saga is Orchestration (as opposed to Choreography). We need a central “Orchestrator” (our mechanical brain state machine) that is responsible for monitoring the progress, detecting failure, and executing the rollback sequence. The LLM does not handle the rollback. The LLM does not know how to handle rollbacks. The deterministic Python infrastructure does.
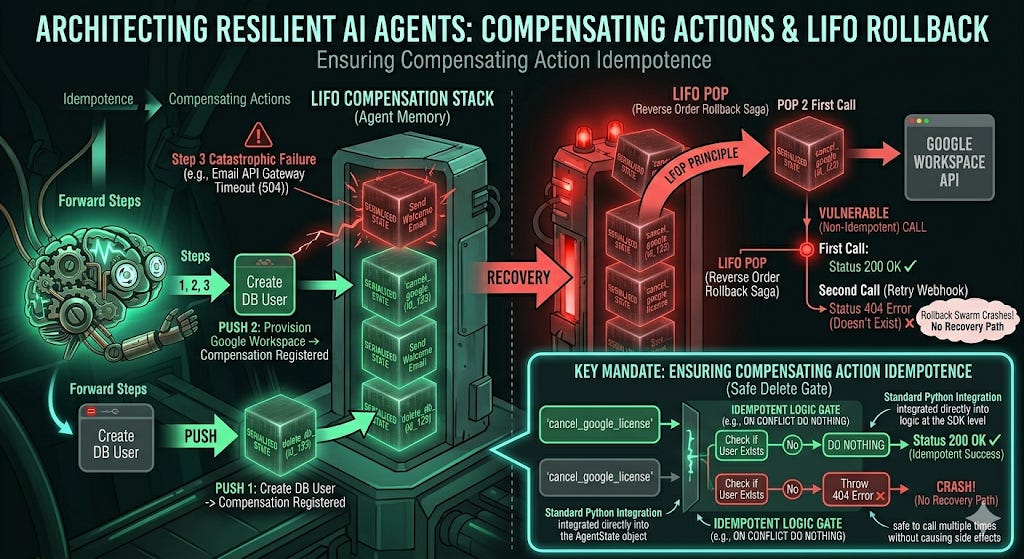
Key Constraint: Ensuring Compensating Action Idempotence
When designing your Compensating Actions (e.g., deleting a user), there is a mandatory engineering requirement you must follow: Idempotence.
A Compensating Action must be safe to call multiple times without causing side effects. When your system is rolling back 72 hours of work, it is entirely possible that a webhook will retry, or a network failure will cause your orchestrator to call “Delete User” twice.
If your “Delete User” function is designed only for the happy path and throws an error the second time because the user doesn’t exist, your rollback swarm will crash, and your enterprise will be left in a corrupted state with no recovery path. Your delete API calls must include if exists or ON CONFLICT DO NOTHING logic at the SDK level.
Implementing the State Machine: The Compensation Stack
To build this architecture, we have to move away from linear arrays of tasks and use our State Machine (like LangGraph or a custom Python loop) to systematically maintain a Compensation Stack.
The concept is simple: as the agent successfully executes forward steps, it deterministicly pushes the exact opposite function to a “Last-In, First-Out” (LIFO) stack. If catastrophic failure occurs, the stack must be popped from top to bottom, undoing the mess in the reverse order of execution. This is the LIFO order required by distributed transactions: (Step 3 failure) -> (Pop Compensation 2) -> (Pop Compensation 1).
Notice how the following code uses standard Python, integrating the rollback stack directly into the AgentState object. It demonstrates a LIFO (Last-In, First-Out) stack without getting bogged down in unreadable boilerplate, ensuring the core concept remains crystal clear.
Python
from typing import List, Dict, Callable
# 1. Define the Agent's Stateful object, including the LIFO stack for rollbacks
class AgentState:
def __init__(self):
self.history: List[str] = []
# The Rollback Stack (LIFO: Last-In, First-Out)
self.compensation_stack: List[Callable] = []
self.status: str = "RUNNING"
self.new_hire_id: str = "123"
# Establish the global State Object
state = AgentState()
# 2. Define your Tools AND their exact opposites (Compensating Saga)
def create_db_user(user_data: dict):
# Action: Insert into DB
print(f"[ACTION] Inserting user {user_data['email']} into DB...")
db.insert("users", user_data)
# 3. Immediately define and push the exact UNDO function to the stack
# Crucially, the UNDO must use the JIT (Just-In-Time) contextual data (user_id)
def rollback_db_user():
print(f"[ROLLBACK] Deleting phantom user {user_data['id']} from DB...")
db.delete("users", user_data['id'])
state.compensation_stack.append(rollback_db_user)
return "User created."
def provision_workspace(user_data: dict):
# Action: Call Google API
print(f"[ACTION] Provisioning Google Workspace license for {user_data['email']}...")
# *idempotent check implicitly* (e.g., check if already exists)
api.create_workspace(user_data)
# 3. Immediately define and push the exact UNDO function to the stack
def rollback_workspace():
print(f"[ROLLBACK] Canceling Google Workspace license for {user_data['email']}...")
# *idempotent check implicitly* (ON CONFLICT DO NOTHING / handle missing case gracefully)
api.delete_workspace(user_data['email'])
state.compensation_stack.append(rollback_workspace)
return "Workspace provisioned."
# 4. The Deterministic Orchestrator Execution Loop (State Machine)
try:
print("Orchestrator executing Step 1...")
create_db_user({"id": state.new_hire_id, "email": "ashu@company.com"})
state.history.append("Created DB User")
print("Orchestrator executing Step 2...")
provision_workspace({"id": state.new_hire_id, "email": "ashu@company.com"})
state.history.append("Provisioned Workspace")
print("Orchestrator executing Step 3...")
# Simulate an API failure or LLM hallucination (A non-deterministic error)
# E.g., The rate limit snaps, or a random payload validation fails.
raise Exception("Email API Gateway Timeout (504)")
# 5. Recovery: Shifting to the Compensating Saga path
except Exception as e:
print(f"\n[SYSTEM FAILURE] Agent crashed: {e}")
print("[SYSTEM RECOVERY] Catastrophic failure detected. Initiating Compensating Saga...\n")
state.status = "ROLLBACK_IN_PROGRESS"
# SYSTEMATICALLY POPS FUNCTIONS OFF THE STACK AND EXECUTES THEM (LIFO)
# This undoes Step 2, then Step 1, returning state to atomic clean.
while state.compensation_stack:
compensating_action = state.compensation_stack.pop()
compensating_action()
state.status = "FAILED_AND_ROLLED_BACK"
print("\n[SYSTEM SAFE] All phantom data removed. State is clean.")
print(f"Audit Trail of failure: {state.history}")
The Executive Mandate: Reliability, Auditability, and Control
When an enterprise chooses an Agentic Platform, they are not just looking for a cool chatbot to answer emails. They are looking for a reliable software system to execute business-critical operations.
Reliability in the enterprise is not about building systems that never make mistakes. Non-deterministic models will make mistakes, frequently. True enterprise reliability is about architecting systems that are deterministicly robust—meaning they always know exactly how to recover safely from any non-deterministic error.
If you cannot deterministically audit your AI’s decisions at scale—specifically, why it made an action and how it recovered from a failure—you do not have an enterprise product; you have a massive legal and financial liability.
InfoSec reviews don’t just care about security; they care about Control. A forward-only agent that crashes and leaves corrupted data is out of control. An agentic swarm architected with Zero-Trust Sidecars, GraphRAG-based Memory, State Rehydration, and now Compensating Sagas is a system under control. By implementing a Compensation Stack alongside your Agent State, you guarantee that your AI either completes its entire job flawlessly, or it leaves no trace that it was ever there.
Stop building happy paths. Start building rollbacks.
Over to you: How are you handling rollbacks?
Are you currently relying on basic try/except blocks to catch your AI’s mistakes and assuming success, or have you started architecting stateful, Compensation Sagas for multi-step swarms?
Drop a comment and let me know how you are handling half-finished agent workflows in production.
Hmm, your solution is to create a kind of resilient workflow...
Just as an engineer would do when programming a procedure\script
So, not much difference between this an actually creating a procedure\script.
Th advantage of the latter is that predictability staggers: less room for the procedure to go the wrong path, better checks and escapes when things go wrong.
And: the 'drawing board' should always include more than just the happy flow!