
Your Agent Passed the Eval and Still Failed Production
Green evals do not mean your agent is ready for messy users, stale context, tool failures, and policy drift.

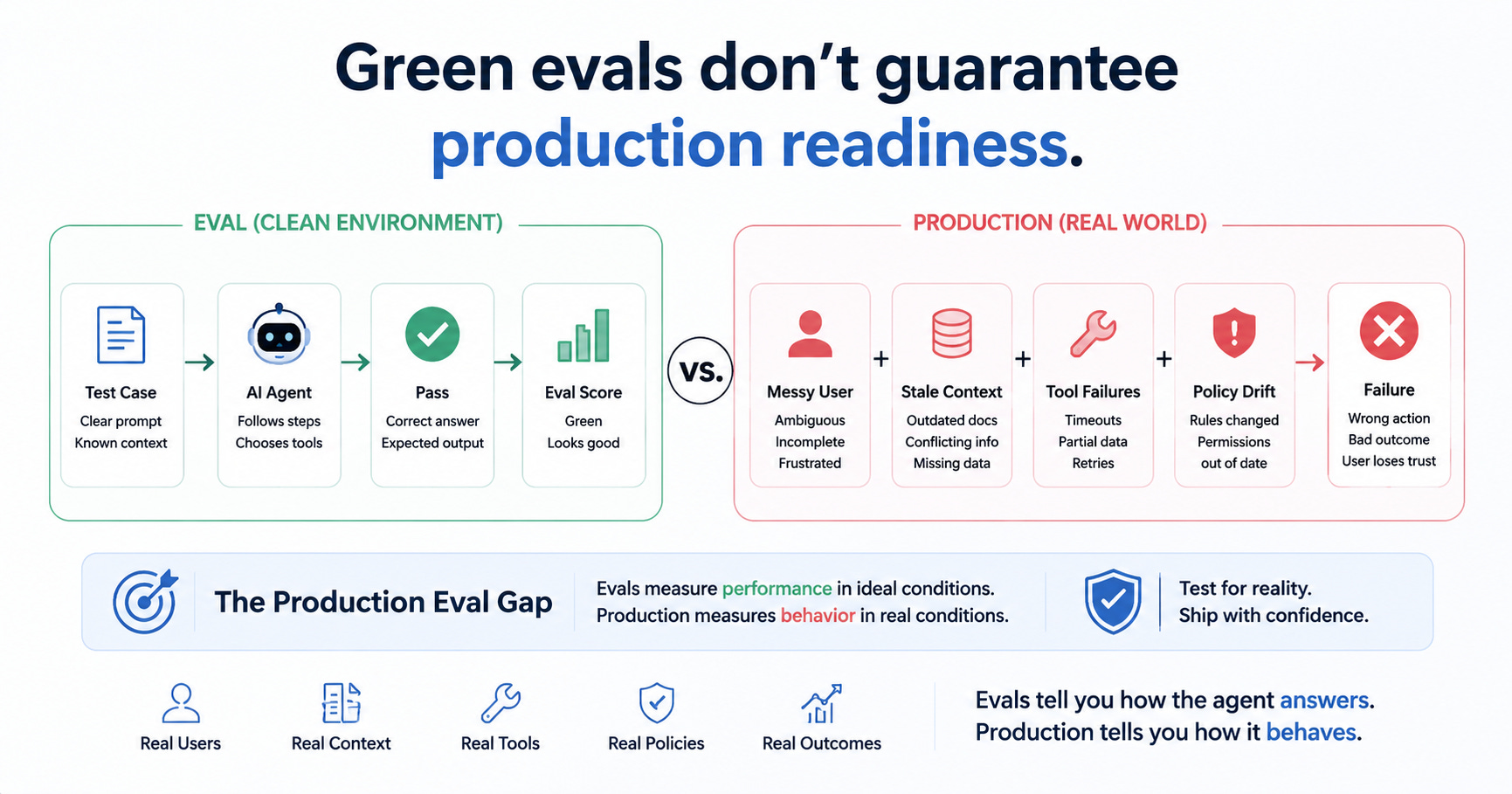
The eval dashboard was green.
The agent passed the golden dataset.
It answered the test questions correctly.
It chose the right tool in the happy-path workflows.
It stayed inside policy on the examples the team had prepared.
The demo looked stable.
Then production happened.
A real user asked the same question with missing context.
The refund policy had changed last week.
The retrieved document was stale.
The billing API timed out once and returned partial data on the retry.
The customer was frustrated and used language that never appeared in the test set.
The agent still answered confidently.
And it failed.
This is the gap many teams discover too late:
Passing evals is not the same as being production-ready.
The eval did its job.
It tested the cases it knew how to test.
Production tested everything else.
I call this the Production Eval Gap.
It is what happens when an agent passes controlled tests but fails under real operating conditions: messy context, changing policies, unreliable tools, ambiguous users, unexpected edge cases, and business risk.
The eval was clean. Production was not.
Most agent evals are too clean.
The prompt is stable.
The user request is clear.
The expected answer is known.
The documents are current.
The tool works.
The test case ends when the answer is generated.
That is useful for early validation.
But production is not clean.
Users do not ask questions the way your eval dataset asks them.
Policies do not stay frozen.
Documents conflict.
APIs fail.
Permissions vary by user.
Memory changes the context.
A correct answer may still be unsafe if the agent takes the wrong action.
The agent does not fail because the eval was useless.
It fails because the eval was incomplete.
It measured answer quality in a controlled environment.
Production requires behavior quality in a live system.
Those are different things.
A correct answer can still be a failed outcome
A support agent answers a billing question.
The answer is factually correct.
The language is polite.
The citation points to a real policy.
The eval marks it as a pass.
But the user still reopens the ticket because the answer did not explain what they should do next.
Was that a success?
A DevOps agent diagnoses an incident.
It correctly identifies a likely cause.
It summarizes the logs.
It recommends a restart.
But it does not notice that the same service was restarted twice in the last hour and the circuit breaker is already open.
Was that a success?
A sales agent drafts a customer follow-up.
The draft is clear.
The tone is good.
The CRM fields are updated.
But the agent used outdated pricing language from an old proposal.
Was that a success?
This is where many evals break down.
They score the output.
Production cares about the outcome.
The better question is not only:
Did the agent produce the right answer?
It is:
Did the agent make the right move under the actual constraints of the workflow?
That means the eval has to include context, tools, permissions, risk, and downstream effects.
The hidden failure: tool behavior
Agent evals often test what the model says.
They do not test what the system does.
That is a problem because production agents do not just generate text. They call tools.
A tool can fail.
A tool can return stale data.
A tool can return partial data.
A tool can expose data the agent should not use.
A tool can succeed technically but create the wrong business outcome.
If your eval only checks the final response, it may miss the most important part of the run.
The agent may have called the wrong tool.
It may have retried too many times.
It may have ignored a failed response.
It may have used cached data as if it were fresh.
It may have taken an action that should have required approval.
A production eval should inspect the whole trace:
What did the agent retrieve?
Which tool did it call?
What did the tool return?
What did the agent do after failure?
Did it respect permissions?
Did it escalate at the right time?
Did it stay within cost and latency limits?
If the tool path is wrong, a polished final answer does not save the system.
Your golden dataset is probably too polite
Golden datasets are useful.
They create a shared baseline.
They make regression visible.
They help teams compare prompts, models, and retrieval changes.
But many golden datasets are too polite.
They contain clean examples written by the team building the agent.
Production users are not that cooperative.
They ask incomplete questions.
They mix two problems into one request.
They use screenshots, slang, anger, abbreviations, and missing details.
They challenge the policy.
They ask for exceptions.
They provide misleading context.
They change their mind halfway through the workflow.
If your eval set does not include messy users, it is not testing production behavior.
It is testing whether the agent can pass your team’s imagination of production.
That is not enough.
A stronger eval set should include:
ambiguous requests
missing fields
outdated documents
conflicting policies
failed tool calls
permission boundaries
repeated user frustration
high-impact actions
edge cases from real support, sales, ops, or engineering workflows
The goal is not to make the agent look good.
The goal is to find where it breaks before users do.
Model-graded evals are not enough
LLM-as-a-judge can help.
It can review tone, completeness, relevance, and basic reasoning quality.
But model-graded evals become dangerous when they are treated as the final authority.
A judge model can say an answer looks good.
It may not know that the policy is stale.
It may not know that the tool call violated a permission boundary.
It may not know that the response created a compliance risk.
It may not know that the user came back two hours later with the same unresolved issue.
For production agents, some evals must be system-level.
You need checks that are not just opinion-based.
Did the agent call the allowed tool?
Did it use the latest policy version?
Did it avoid restricted data?
Did it stay under the retry limit?
Did it escalate high-risk cases?
Did the user reopen the issue?
Did the workflow reach a safe state?
The judge model can review the answer.
The system should verify the behavior.
The eval should test failure handling
A production-ready agent is not the one that performs well only when everything works.
It is the one that behaves safely when something breaks.
So your evals should not only test the happy path.
They should test what happens when:
The retrieval result is empty.
The retrieved documents disagree.
The API times out.
The tool returns partial data.
The user asks for something outside policy.
The agent reaches the retry limit.
The cost per task crosses the budget.
The action requires human approval.
The context contains stale memory.
This is where agent quality becomes visible.
Does the agent guess?
Does it retry forever?
Does it escalate?
Does it explain uncertainty?
Does it move to draft-only mode?
Does it stop before taking a risky action?
A good eval does not just ask:
Can the agent succeed?
It asks:
Can the agent fail safely?
The real production eval loop
The mistake is treating evals as a launch gate only.
Run evals.
Get green score.
Ship the agent.
Move on.
That is not how agentic systems behave.
Prompts change.
Models change.
Documents change.
Tools change.
Policies change.
User behavior changes.
Memory changes.
The business process changes.
Every one of those changes can break behavior that used to work.
So evals need to become a production loop.
Before launch, they test readiness.
During launch, they monitor live behavior.
After launch, they catch regressions.
After incidents, they add new failure cases.
Every real production failure should become a new eval.
That is how the system learns.
Not by hoping the agent gets smarter.
By turning failures into tests.
The question to ask before launch
Before shipping an agent, do not only ask:
What is the eval score?
Ask:
What kinds of production failure can this eval not see?
That question is more useful.
It exposes the blind spots.
Maybe your eval cannot see tool misuse.
Maybe it cannot see stale retrieval.
Maybe it cannot see permission leaks.
Maybe it cannot see repeated user frustration.
Maybe it cannot see cost spikes.
Maybe it cannot see whether the final answer changed the outcome.
Those blind spots are where production incidents come from.
A green dashboard is comforting.
A known failure boundary is useful.
Final thought
Evals are not the problem.
Weak evals are.
A good eval program does not exist to prove the agent is smart.
It exists to reveal where the agent is unsafe, brittle, expensive, overconfident, or unready for real workflows.
The best teams will not be the ones with the prettiest demo or the highest eval score.
They will be the ones that know exactly where their agent fails, how it fails, and what the system should do when it fails.
That is production readiness.
Not green tests.
Known behavior under messy conditions.
Launch Gate
Below 24/35, the agent is not production-ready.
At 24–30, the agent may be usable in limited scope with monitoring and human review.
At 31+, the eval program is closer to production-grade, assuming live monitoring and audit trails are also in place.
Final question
What can this eval not see?
Write the answer before launch. That is your production risk backlog.