
The Swagger Trap: Why Feeding Raw APIs to LLMs is a Direct Deposit to OpenAI
Stop feeding your company’s OpenAPI spec directly to the LLM. It’s time to engineer deterministic tool abstraction layers.


Over the last several flagship posts, we have covered the hardcore architectural realities of building and deploying Agentic AI. We’ve discussed why traditional CI/CD fails for probabilistic models, why you need deterministic Zero-Trust Sidecars for security, and why you must Stop Testing AI on Live Users by adopting Shadow Mode.
By now, your organization is likely convinced of the architecture and is ready to write the logic. Your engineers are loading up LangGraph or AutoGen, and they are preparing to give their agents capabilities.
And this is where 99% of engineering teams fall into the single most dangerous hype-trap in the 2026 AI ecosystem.
The hype sounds incredibly seductive: “Just feed your autonomous agent your company’s existing OpenAPI (Swagger) spec, and the LLM will magically figure out exactly how to invoke your internal REST APIs to get work done!”
This is a complete, unadulterated delusion.
If you attempt to load a complex, production-grade OpenAPI spec directly into an LLM’s tool context window and ask it to execute multi-step tool calls against a database, you will not have an autonomous agent. You will have a localized DDOS attack on your own infrastructure, stuck in an infinite retry-loop, hallucinating non-existent parameters while generating a massive OpenAI API bill.
This post is a reality check. We will dissect exactly why this approach fails, walk through a post-mortem of a failed tool call, and then engineer the only reliable alternative: the Tool Abstraction Layer.
Chapter 1: We are treating heuristic engines like deterministic API clients.
The fundamental delusion of the “OpenAPI spec hype” is a failure of semantic understanding. We are confusing data description with cognitive understanding.
An OpenAPI specification is a deterministic, syntactic contract written in YAML or JSON. It describes exactly what endpoints exist, what methods they support (GET/POST/DELETE), what headers are required, and the precise JSON schema for input payloads. It is designed to be ingested by other deterministic machines (like code generators or postman).
A Large Language Model is a probabilistic heuristic compute component. It is a text generation function that predicts the most likely next token. It does not “understand” an API contract. It does not “read” YAML. It converts the YAML text into statistical vector representations and tries to generate text that looks like it adheres to that structure.
When you ask an LLM to call an API directly from its spec, you are essentially giving a high-speed calculator a poetry book and asking it to solve a partial differential equation based on the “vibe” of the meter.
It fails because of two architectural constraints: the Probabilistic Execution Gap and the Semantic Dilution Problem.
Chapter 2: The Anatomy of an API Tool Call Failure (Visual & post-mortem)
Let’s visualize the current industry “Happy Path” and look at what actually happens when the state machine tries to use a complex OpenAPI spec.
The Spec Example: Creating a User in a Legacy CRM
Consider this slightly complex API endpoint from a company’s CRM system. It isn’t just POST /users. To prevent spam, the legacy CRM requires:
Strict Payload: A nested JSON object.
Required Enum: A
user_typeparameter that must be either"internal_staff"or"vetted_customer".Required Header: An
X-CRM-Source-Appheader (e.g.,"web") that must accompany every write operation.
Visualizing the Delusion
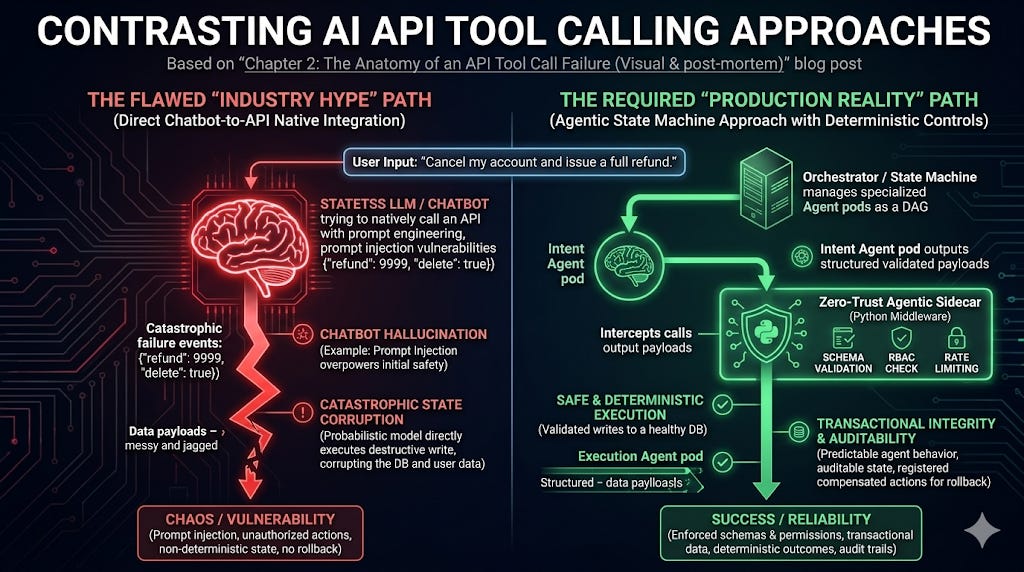
The Post-Mortem of the Industry Hype Approach
Now, let’s walk through the trace log of what actually happens when we ask the LLM (V1) to create a user for “Ashu”:
The Orchestrator Loop:
User Input: “Create an internal staff account for Ashu Kumar, ashu@corp.com.”
State Machine: Calls the LLM Node. The system prompt includes the 400-line OpenAPI YAML spec for the CRM.
LLM Inference: Reads the YAML. Understands semantically that
POST /usersis the tool. Generates the tool-invocation call:
JSON
// --- The LLM (probabilistically) generated this ---
{
"tool_name": "crm_create_user",
"tool_id": "crm:post_users_v2",
"params": {
"full_name": "Ashu Kumar",
"email": "ashu@corp.com",
"user_type": "employee" // --- FAILURE 1: Hallucination ---
}
}
The Breakdown of the Errors:
Failure 1: Hallucination (Enum Violation): The OpenAPI spec strictly defined the enum as
["internal_staff", "vetted_customer"]. But the system prompt also mentioned the words “employee” and “staff.” The LLM, operating probabilistically, statistically linked “employee” to “internal staff” and outputted the most semantically probable string, ignoring the syntactic constraint of the YAML enum.Failure 2: Syntax Error (Malformation): The API contract required a nested object:
{"data": {"email": "ashu@corp.com", ...}}. The LLM flattened the payload because its training data is filled with flatter JSON structures.Failure 3: The Silent Omission (Missing Header): The LLM did not generate the mandatory
X-CRM-Source-App: "web"header. Headers are often defined at the root of an OpenAPI spec, far away from the individual endpoint definition. The LLM’s attention mechanism diluted over the 400-line spec, and it simply forgot about the root requirement.
The Catastrophic Retry Loop:
The Python Sidecar receives the malformed JSON. It executes the REST call. The CRM server predictably returns a 400 Bad Request.
The Sidecar returns this error to the state machine: *”Error: CRM API returned 400 Bad Request. Parameter user_type must be in enum [’internal_staff’, ‘vetted_customer’].”
Now, the state machine calls the LLM node again to “Fix the error.”
The LLM reads its previous error: “Oh, ‘employee’ was wrong. I should try ‘staff’ because the input said ‘staff’!” It generates a new failing call. If you don’t have hard circuit breakers, this loop runs infinitely until you max out your OpenAI token budget or your internal database rate-limiter collapses under the load.
Chapter 3: The 4 Reasons the OpenAPI Spec is a Context Nightmare
We’ve seen the execution failure. But even if we could fix the hallucinations, loading a raw OpenAPI spec directly is a catastrophic architectural flaw for four specific engineering reasons.
1. It is a Catastrophic Waste of Tokens
A standard OpenAPI YAML spec for a moderately complex microservice can easily run 500 to 1,000 lines. Loading that into the system prompt costs money on every single execution turn. If your agent needs five steps to solve a problem, you are rebroadcasting that 1,000-line spec five times. This is infrastructure malpractice. Token engineering is now cost engineering.
2. Semantic Dilution and The “Lost in the Middle” Effect
When you give an LLM a context window filled with 400 lines of API specs describing 20 different endpoints, you are suffering from Semantic Dilution. The model’s finite attention mechanism is stretched too thin.
It loses its focus. It gets confused by the similarity of parameters across different methods (e.g., should it use the userId path parameter for the GET call or the userId body parameter for the POST call?). This confusion dramatically increases the probability that it will execute the wrong tool for the right reason.
3. The Brittle Versioning Problem
API specs change. Your backend team updates a field from snake_case to camelCase or adds a mandatory parameter. If you are feeding the raw spec to the agent, you now have to update your system prompt, which means you have to rerun all your evaluations to ensure the prompt update didn’t introduce new, unexpected hallucinations. Your agentic reliability is now coupled to your backend team’s deployment cycle. This is technical debt on arrival.
4. It Breaches Architectural Boundaries (Zero-Trust Violation)
In our golden rules of Agentic Security, we established that agents should never touch infrastructure directly. A system that reads the raw OpenAPI spec and relies on the prompt to adhere to rules (like “You must never execute DELETE calls”) is operating on an honor system. Security must be enforced by a deterministic layer, not probabilistic text instructions.
Chapter 4: The Remedy: The Tool Abstraction Layer
We have to stop treating LLMs like senior software engineers who can read documentation. We must treat them like highly volatile compute components that require aggressive, deterministic scaffolding to function reliably.
You must implement a Tool Abstraction Layer (TAL) between the LLM and the raw API.
The Concept: Split the Responsibility
The fundamental shift is moving responsibility away from the LLM.
The LLM’s Role (Heuristic): Convert the user’s unstructured English input (”Ashu Kumar, internal staff”) into the most minimal, structured, non-ambiguous identifiers (e.g., the string
"ashu_kumar"). The LLM is banned from constructing massive JSON payloads, nested objects, or handling header requirements.The Python TAL (Deterministic): Take the LLM’s minimal output (the identifier). Run deterministic Python code to look up that identifier, validate the context, construct the complex, nested JSON payload, inject the required
X-CRM-Source-Appheaders, and actually execute the tool.
We are replacing probabilistic text generation with hardcoded Python logic. This is how you build a resilient, fault-tolerant system.
Chapter 5: Building a “Dumb Tool” (Python Blueprint)
Let’s re-engineer our failing CRM user creation call using the Dumb Tool approach within the Abstraction Layer.
We will define what the LLM sees, and then write the code that actually executes.
Step 1: Defining the “Dumb Tool” (What the LLM Sees)
We will use LangChain/LangGraph’s structured tool decorator to present the LLM with an incredibly minimal interface. Note how the LLM is banned from seeing the complex YAML enum. We just ask for the user type as an English string. We also don’t mention headers or the nested JSON schema.
Python
from langchain_core.tools import tool
from pydantic import BaseModel, Field
# We define the minimal inputs we want from the Heuristic engine.
# We do not ask it to handle complex API-specific structures.
class MinimalCrmUserInput(BaseModel):
fullname: str = Field(description="The user's first and last name.")
email: str = Field(description="The validated corp email address.")
employment_type: str = Field(
description="Must be semantically equivalent to 'internal staff' or 'customer'."
)
# --- THE "DUMB TOOL" DEFINITION ---
# This minimal description is ALL the LLM sees in its context.
# Token cost is minimized. Semantic Dilution is avoided.
@tool("deterministic_crm_create_user", args_schema=MinimalCrmUserInput)
def deterministic_crm_create_user(inputs: MinimalCrmUserInput):
"""
Deterministically creates a user in the CRM system using validated mappings.
Returns the CRM User ID or a detailed system error.
"""
# ---------------------------------------------------------
# --- Step 2: The Deterministic Abstraction Layer (TAL) ---
# ---------------------------------------------------------
print(f"[TAL] LLM generated minimal inputs: {inputs.dict()}")
# --- TAL TASK 1: Deterministic Heuristic Mapping (Enum Fixing) ---
# We map the LLM's semantic English back to the brittle syntactic enum
# required by the raw legacy API. This can be regex or a switch.
employment_str = inputs.employment_type.lower()
if any(x in employment_str for x in ["staff", "employee", "internal"]):
validated_enum = "internal_staff"
elif any(x in employment_str for x in ["customer", "client", "vetted"]):
validated_enum = "vetted_customer"
else:
return f"Error: Cannot resolve employment_type '{inputs.employment_type}' to a valid enum."
# --- TAL TASK 2: State Construction (Nested JSON & Mappers) ---
# We, the engineers, construct the brittle nested payload.
# We do not rely on the LLM to figure out "UsrData".
raw_api_payload = {
"UsrData": {
"full_name": inputs.fullname,
"usrEmail": inputs.email,
"usr_type": validated_enum, # Insert the valid enum here
"active": "y" # Map boolean true to "y"
}
}
# --- TAL TASK 3: Header Injection & Security ---
# We inject mandatory security headers outside of the LLM context.
headers = {
"X-CRM-Source-App": "agentic-orchestrator",
"Authorization": "Bearer deterministic_internal_api_key",
"Content-Type": "application/json"
}
# --- TAL TASK 4: Safe Execution (API Sidecar) ---
# The Tool Abstraction Layer uses its own secure, deterministic
# client (using `requests` or `httpx`) to call the API.
print(f"[TAL] Constructing secure payload & executing...")
try:
# result = httpx.post("https://legacy-crm.corp/users/v2", json=raw_api_payload, headers=headers)
# mocked_result = {"status": "success", "userId": "crm_ashu_1122"}
# return result.json()
return {"status": "success", "userId": "crm_ashu_1122"}
except Exception as e:
return f"System Error executing CRM API call: {str(e)}"
The Abstraction Vibe Check
Let’s look at why this re-engineering works:
Context Optimization: The prompt is now 10 lines of description, not 400 lines of YAML.
Determinism: The
employment_typehallucination (employeevs.internal_staff) is now caught and deterministicly fixed in Python logic.Resilience: The header requirement is hardcoded; the agent can’t forget it. The nested JSON schema is handled by the TAL, not the LLM.
Security: The API token is securely held by the PythonTAL, not exposed to the LLM context window where a prompt injection attack could steal it.
Chapter 6: The Executive Mandate: Stop Asking AI Nicely. Start Engineering Scaffolding.
The era of prompt engineering is over. The era of agentic infrastructure has begun.
The “OpenAPI spec hype” is built on a dangerous fundamental assumption: that LLMs are a more flexible type of traditional software. But traditional software is deterministic. It requires syntactic contracts and rigid execution paths. AI is probabilistic.
When you attempt to marry a probabilistic text generator to a rigid syntactic API contract, you are engineering a disaster. You are maximizing hallucination risk, token costs, and technical debt.
To survive the agentic transition, you must accept that the “Compute Layer” (the LLM) is inherently volatile. Your product is not defined by the model you choose; your product is defined by the quality of the deterministic scaffolding (the state machines, the Zero-Trust Sidecars, and the Tool Abstraction Layers) that you build around that volatile core.
Stop writing English to a black box. Start building state machines that intercept and validate every cognitive thought before it becomes a production API action.
Over to you: How is your team currently handling tool calling? Are you struggling with OpenAPI spec context limits and malformed JSON payloads, or have you already deployed Tool Abstraction Layers? Let’s debate the stack in the comments.
1000%